Rafraîchir le blog — encore une fois

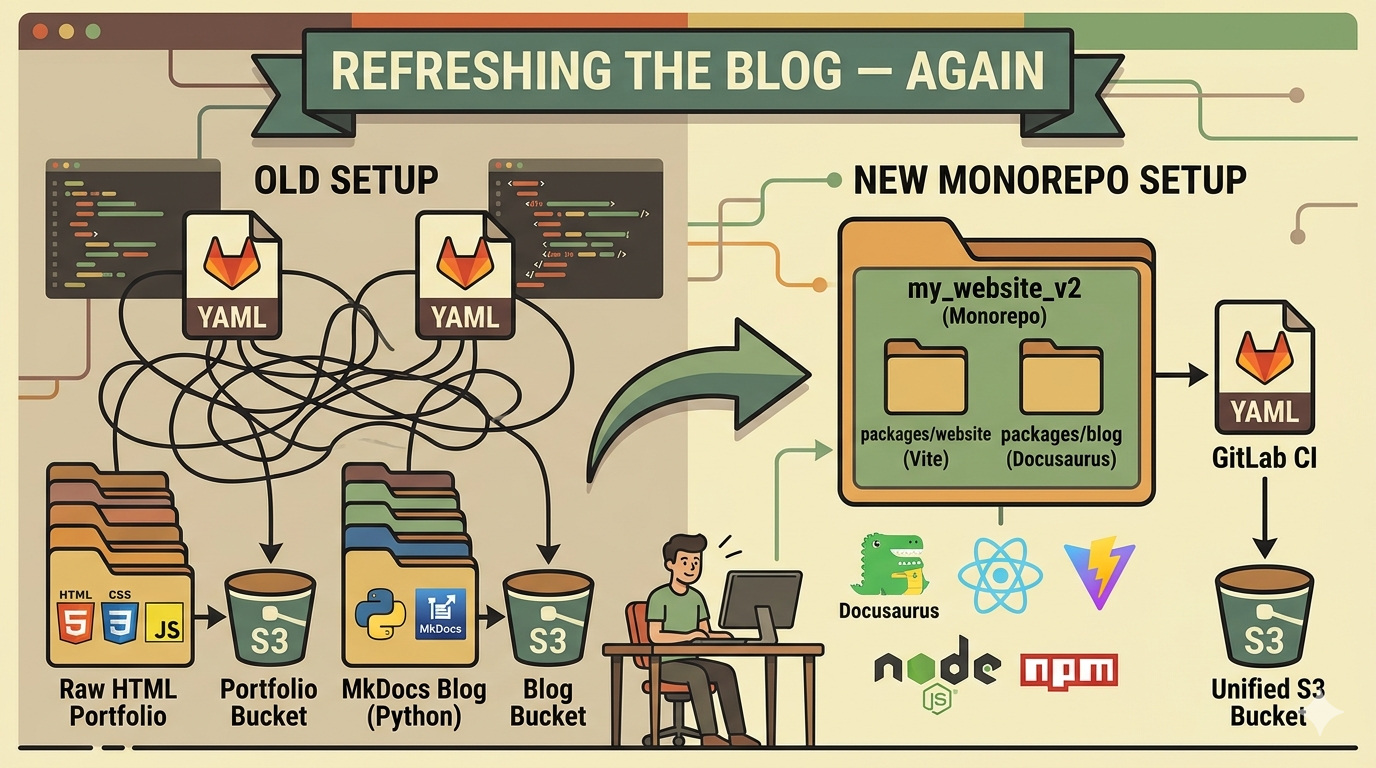
Il y a quelque temps j'ai écrit un article sur comment j'avais créé ce blog. À l'époque c'était Pelican, un générateur de site statique en Python. Ensuite je l'ai migré vers MkDocs — toujours en Python, un peu plus moderne, un meilleur support pour mon setup bilingue. Et nous voilà encore. Troisième fois.
Voici l'histoire de pourquoi je l'ai fait et comment ça s'est passé.
Si vous lisez ceci sur le blog, c'est que la migration est terminée. Félicitations, vous avez survécu à la downtime.
L'ancien setup
Laissez-moi décrire ce que j'avais avant pour que vous compreniez pourquoi je voulais changer.
Le portfolio
Un site HTML/CSS/JavaScript brut. Pas d'étape de build. Pas de bundler. Juste des fichiers sur un disque que j'uploadais sur S3.
Ça fonctionnait. Mais c'était douloureux à maintenir. Tout le CSS était dans un seul fichier de 600 lignes mélangeant couleurs, mise en page et composants. Il n'y avait pas de séparation claire entre les données et la présentation. Le JavaScript était procédural, avec des appels à eval() pour mapper des noms de propriétés en chaînes de caractères vers des attributs DOM. Les dépendances étaient chargées depuis des CDN avec des numéros de version codés en dur dans des balises <script>.
À chaque fois que je devais toucher quelque chose, je devais redécouvrir comment c'était assemblé.
Le blog
MkDocs est un générateur de site statique tout à fait correct. Je n'ai rien de négatif à dire dessus. Mais c'était un projet séparé, avec son propre environnement Python, son propre pipeline GitLab CI, et son propre processus de déploiement S3. Deux projets, deux pipelines, deux processus de déploiement.
Et MkDocs n'est pas vraiment conçu pour un blog. J'utilisais le plugin Blog de MkDocs Material qui est très bien mais qui ajoute une couche sur quelque chose qui n'a pas été construit pour ce cas d'usage dès le départ.
La situation CI
Deux fichiers .gitlab-ci.yml. Deux stratégies de cache séparées. Deux jobs de déploiement séparés. Quand je voulais faire un changement qui touchait à la fois le portfolio et le blog — comme mettre à jour les liens du footer — je devais coordonner deux pipelines séparés et deux déploiements séparés. C'était pénible.
Pourquoi Docusaurus et Vite
Docusaurus
Docusaurus est un générateur de site statique basé sur React fait par Meta, principalement conçu pour la documentation. Mais il a un mode blog qui est assez bon. Il supporte :
- Le contenu bilingue nativement avec son système i18n
- L'estimation du temps de lecture
- Les profils d'auteurs
- Les flux RSS/Atom
- Les pages de tags
Il est construit sur Node.js et npm, ce qui signifie que je suis de retour dans l'écosystème que je déteste mais au moins c'est le même écosystème que les outils de build du portfolio. La cohérence a une valeur.
J'ai considéré Astro et 11ty. Astro est intéressant mais il nécessitait plus de configuration pour le même résultat. 11ty est élégant dans sa simplicité mais le support i18n de Docusaurus est difficile à égaler sans l'écrire soi-même.
Vite
Vite est le choix évident pour le portfolio. C'est rapide, ça gère bien les applications multi-pages, et il a un support de première classe pour les ES modules. La migration du HTML brut + JavaScript procédural vers une vraie application multi-pages Vite m'a donné la structure dont j'avais besoin sans me forcer à adopter un framework de composants.
La structure monorepo
La décision de fusionner les deux projets en un seul dépôt était la plus importante. Tout le reste en découle.
my_website_v2/
├── package.json # racine npm workspaces
├── packages/
│ ├── website/ # portfolio Vite
│ └── blog/ # blog Docusaurus
└── dist/ # output assemblé
Le package.json racine déclare les deux packages comme npm workspaces et orchestre le build :
{
"scripts": {
"build": "npm run build:website && npm run build:blog && npm run assemble",
"assemble": "mkdir -p dist && cp -r packages/website/dist/. dist/ && mkdir -p dist/blog && cp -r packages/blog/build/. dist/blog/"
}
}
Le portfolio se build dans dist/, le blog se build dans dist/blog/. La structure d'URL est préservée : / pour le portfolio, /blog/ pour le blog. Une seule commande rclone sync en CI pour tout pousser vers S3.
Migration du portfolio
Refactoring CSS
La première chose que j'ai faite a été d'extraire la palette de couleurs Gruvbox en propriétés CSS personnalisées :
:root {
--gb-bg: #1d2021;
--gb-bg1: #282828;
--gb-fg: #ebdbb2;
--gb-cyan: #689d6a;
--gb-yellow: #d79921;
/* ... */
}
Ensuite j'ai remplacé chaque couleur codée en dur dans les feuilles de style des composants par ces variables. Aucun changement visuel, mais maintenant le thème est en un seul endroit.
Modules JavaScript
Le principal défi était le pattern eval(). Le code original utilisait des noms de propriétés en chaîne pour définir des variables CSS dynamiques :
// Avant
config.forEach(function(item) {
Object.keys(item).forEach(function(key) {
eval("element." + key + " = item[key]");
});
});
Je l'ai remplacé par une map de propriétés explicite :
// Après
const PROPERTY_MAP = {
textContent: (el, v) => { el.textContent = v },
href: (el, v) => { el.href = v },
style: (el, v) => { el.setAttribute('style', v) },
};
Moins malin, mais ça fonctionne sans eval() et c'est lisible.
UAParser.js
Le portfolio utilise UAParser.js pour afficher le navigateur et l'OS du visiteur sur la homepage terminal. Avant il était chargé depuis un CDN :
<script src="https://cdn.jsdelivr.net/npm/ua-parser-js@1/src/ua-parser.min.js"></script>
Maintenant c'est une dépendance npm correcte importée en tant qu'ES module :
import { UAParser } from 'ua-parser-js'
Migration du contenu du blog
Le script de migration
J'ai écrit un script Node.js à usage unique pour migrer tous les articles MkDocs vers le format Docusaurus. Les principales choses qu'il devait gérer :
Frontmatter : MkDocs Material utilise categories et tags comme champs séparés, Docusaurus n'a que tags. Le script les fusionne et déduplique. Il supprime aussi le champ readtime car Docusaurus calcule automatiquement le temps de lecture.
Admonitions : MkDocs utilise la syntaxe !!! warning "Titre", Docusaurus utilise :::warning[Titre]. Une regex gère la conversion :
content = content.replace(
/^!!!\s+(\w+)(?:\s+"([^"]*)")?\n\n?((?:(?: |\t)[^\n]*\n?)+)/gm,
(_, type, title, body) => {
const dedented = body.replace(/^( |\t)/gm, '')
const header = title ? `:::${type}[${title}]` : `:::${type}`
return `${header}\n${dedented.trim()}\n:::\n`
}
)
Structure des répertoires : Les articles MkDocs sont dans docs/en/posts/slug/index.md sans date dans le chemin. Docusaurus veut blog/YYYY-MM-DD-slug/index.md. Le script lit le champ date: du frontmatter et préfixe le nom du répertoire.
Marqueurs de troncature : MkDocs utilise <!-- more --> pour le cutoff de l'extrait d'article. Docusaurus utilise <!-- truncate -->. Un simple chercher et remplacer.
Contenu bilingue
Les articles EN vont dans packages/blog/blog/. Les articles FR vont dans packages/blog/i18n/fr/docusaurus-plugin-content-blog/. Les images sont stockées avec l'article EN et les articles FR les référencent avec le même chemin relatif — Docusaurus les résout correctement au moment du build.
Les problèmes amusants
Node 25 et l'erreur localStorage
Le build SSG de Docusaurus crashait sur Node.js 25 avec :
Cannot initialize local storage without a --localstorage-file path.
Node.js 25 embarque l'API Web Storage nativement, mais contrairement aux navigateurs, il nécessite un chemin de fichier explicite pour persister les données. Docusaurus utilise localStorage en interne lors du SSG pour la persistance du thème et n'avait aucune idée que cette API nécessitait maintenant une initialisation.
Le fix est un flag Node.js :
NODE_OPTIONS='--localstorage-file=/tmp/docusaurus-ls' docusaurus build
Il est dans le script build du package.json et dans le bloc variables du GitLab CI.
Les espaces insécables
Le HTML réduit les espaces consécutifs ordinaires en un seul. Tout le monde le sait. Moins de monde y pense quand on écrit des chaînes qui seront injectées via innerHTML.
La homepage terminal a deux commandes dont l'affichage repose sur l'alignement en colonnes : locate (les liens sont paddés à une largeur commune avant le commentaire #) et ls -l /bin (les tailles de fichiers et les dates sont alignées à droite). Le code source original utilisait des espaces insécables U+00A0 pour ce padding, pas des espaces normaux. En HTML, ou son équivalent Unicode est le seul caractère d'espacement qui ne se réduit pas.
Pendant la migration, chaque éditeur de texte, outil de diff, et copier-coller impliqué dans le déplacement de ces chaînes a traité U+00A0 comme un espace ordinaire. Ils sont tous ressortis en U+0020. Les colonnes ont disparu silencieusement — pas d'erreur de build, pas d'échec de test, juste une régression cosmétique qu'on ne remarque que si on regarde la page.
Le fix est chirurgical : retrouver le code source original, extraire les octets bruts, les restaurer. Un one-liner Python pour grep le fichier original et compter les occurrences de \xa0 l'a confirmé, puis une substitution directe au niveau des octets les a remis en place.
Leçon : si l'alignement en colonnes dans du HTML est important, utiliser un <pre> ou white-space: pre et garder la chaîne dans un fichier séparé où un linter ne peut pas la toucher.
webpack 5.106 et webpackbar
Docusaurus 3 utilise webpack 5 en interne. webpackbar — le plugin de barre de progression — a été mis à jour vers la version 6.0.1, qui passait des options (name, color, reporters) au ProgressPlugin de webpack. Mais webpack 5.100+ avait supprimé ces options de ProgressPlugin.
Le résultat : le build du blog crashait au démarrage avec une erreur obscure sur les options du plugin.
Le fix a été de fixer webpack à 5.95.0 comme devDependency directe dans packages/blog/package.json. La résolution npm workspaces le récupère et l'utilise à la place de résoudre la dernière version 5.x.
{
"devDependencies": {
"webpack": "5.95.0"
}
}
Pas idéal, mais ça fonctionne jusqu'à ce que Docusaurus publie un fix en amont.
Le pipeline CI
Le nouveau .gitlab-ci.yml est en trois étapes : install, build, deploy.
install → build → pages (branche develop)
→ publish (branche master)
Le job pages copie dist/ vers public/ pour GitLab Pages sur la branche develop. Le job publish lance rclone sync pour pousser dist/ vers S3 sur la branche master.
Avant, j'avais deux pipelines avec deux jobs de déploiement S3 séparés, dont l'un utilisait un pattern d'exclusion pour éviter d'écraser le blog déployé depuis l'autre pipeline. Maintenant c'est un seul rclone sync sans exclusions :
rclone sync --checksum --delete-during --quiet \
--s3-provider AWS \
--s3-access-key-id "$AWS_ACCESS_KEY_ID" \
--s3-secret-access-key "$AWS_SECRET_ACCESS_KEY" \
--s3-region eu-west-3 \
./dist :s3:website-lunik.tiwabbit.fr
--delete-during supprime du bucket les fichiers qui n'existent plus dans dist/ pendant la synchronisation. --checksum utilise des checksums plutôt que les dates de modification pour détecter les changements — plus fiable pour des fichiers réassemblés depuis les mêmes sources. Propre.
Conclusion
Trois itérations de ce blog. Pelican, puis MkDocs, maintenant Docusaurus. À chaque fois les outils s'améliorent et la charge de maintenance diminue.
Le monorepo était le bon choix. Avoir le portfolio et le blog dans le même dépôt, avec le même pipeline de build, est vraiment moins pénible que de maintenir deux projets séparés. J'aurais dû le faire plus tôt.
Le code source est sur gitlab.com/Lunik/my_website_v2.